XOR 문제 다음으로 딥러닝 발전에 암흑기를 가져온 '기울기 사라짐(Vanishing Gradient)'에 대해 공부해본다.

- 인공신경망은 합성함수의 형태로 계산이 되어 결괏값이 나오는 형태이기 때문에, 그 미분은 연쇄 법칙을 통해서 계산이 됨
- 연쇄 법칙은 어떤 미분의 곱들로 계산이 됨
- p1은 활성화 함수 a1에 가중치*x 해준 것
- p1을 w1으로 미분한 값 = a1을 w1으로 미분한 값

- 최종적으로 입력값에 가중치들이 곱해지고 활성화 함수를 미분한 형태들을 볼 수 있음
- 역전파의 형태를 봤더니, 활성화 함수를 미분하는 과정이 들어 있는 것을 알 수 있음

- 빨간색으로 표시된 sigmoid는 스무스한 그래프를 가지고 있음
- sigmoid를 미분하면 파란색 그래프로 표현됨
- sigmoid 미분한 값들을 곱하면 엄청 작은 0에 가까운 수가 됨
- 우리가 구하고자 하는 미분 값이 0에 가까운 수가 될 수 있음
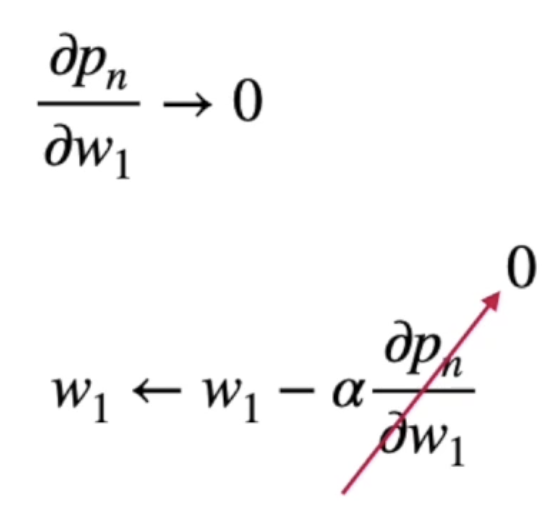
- 우리가 w1에 대해 업데이트하고 싶은데 미분 값이 0으로 가버리게 되면 w1이 되기 때문에
- 다음 가중치가 업데이터 되지 않는 현상이 발생함
- 이 것을 '기울기 사라짐'이라고 함
- 층을 깊게 하면 예측에 좋다고 생각을 했는데, 막상 업데이트를 하려고 하니까 연쇄 법칙이 이뤄지면서 미분 값이 0으로 가버리는 문제가 생김

- ReLU 그래프의 0을 기준으로 왼쪽을 미분하면 0, 오른쪽을 미분하면 1
- 오른쪽 값의 경우 무조건 1이 나오기 때문에 sigmoid 보다는 좋음
- Leaky ReLU 그래프를 사용하여 기울기 사라짐을 더 방지할 수 있음
손실 함수와 최적화에 대해 완벽한 이해가 되지 않더라도, 포인트는 꼭 알고 가자!!
하강법(Descent Method)의 한계
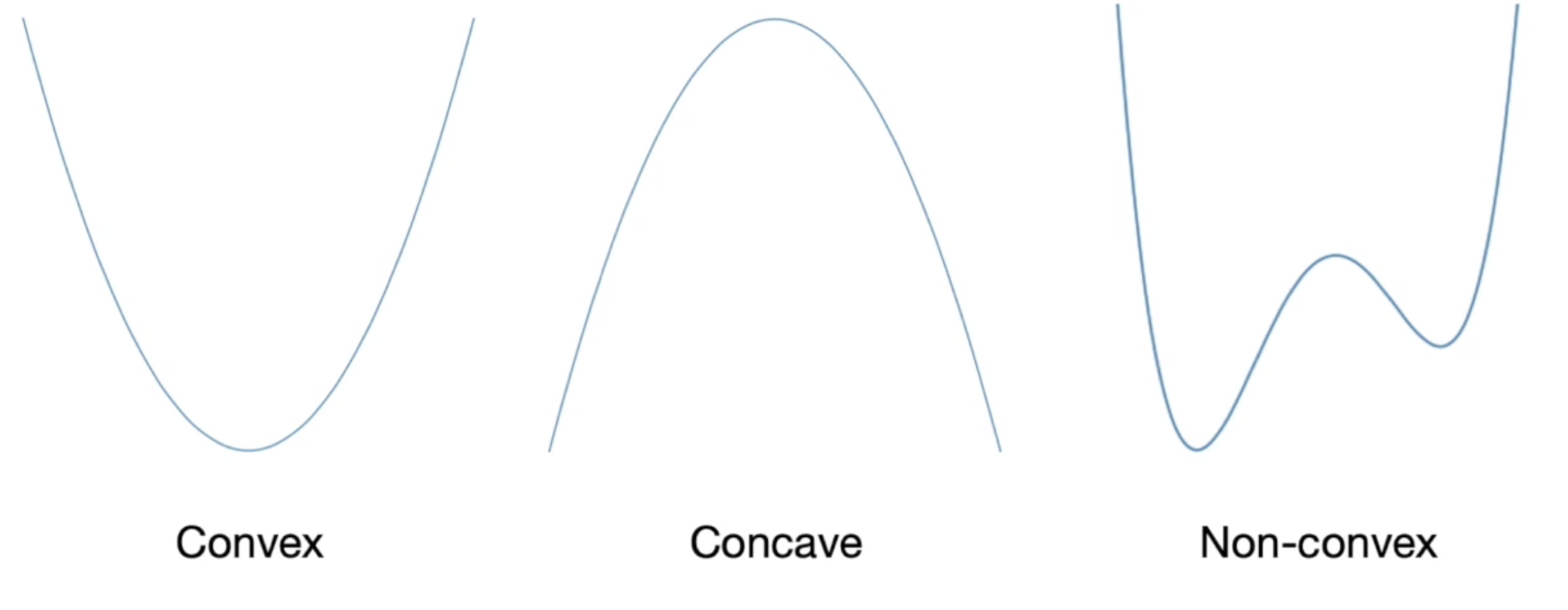
- 손실 함수 설계 시 W형 그래프인 경우 어디가 최솟값인지 알 수 없는 경우가 생기므로 U형 그래프로 설계하는 것이 좋음
- 대표적인 손실 함수(Loss function)의 특징 : MAE, MSE, Cross Entropy 함수는 볼록성(Convexity)을 지님
- Loss Function은 Convex로 설계해주는 것이 가장 좋음
볼록성에 대해서는 아래에서 더 보자!
더보기
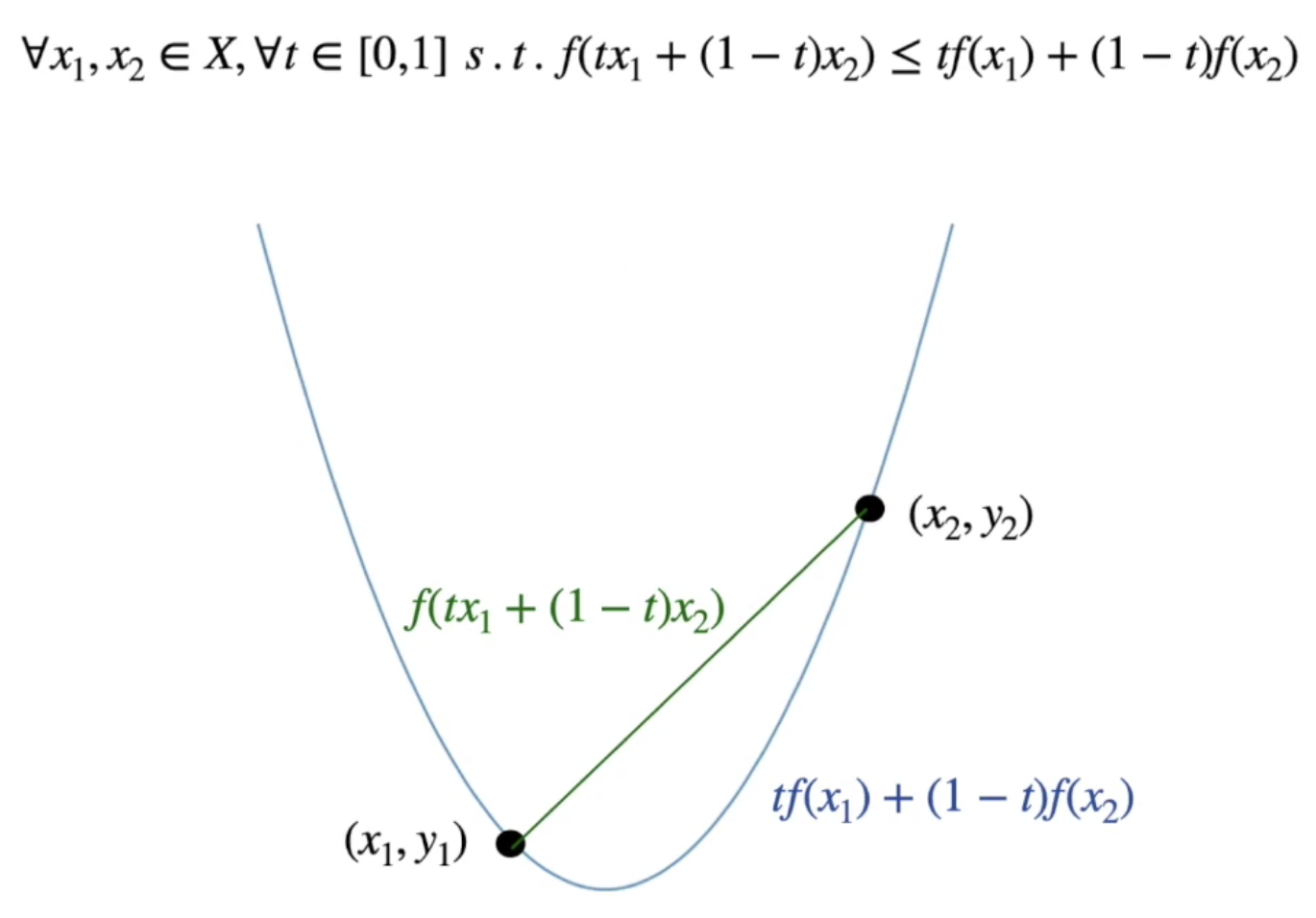
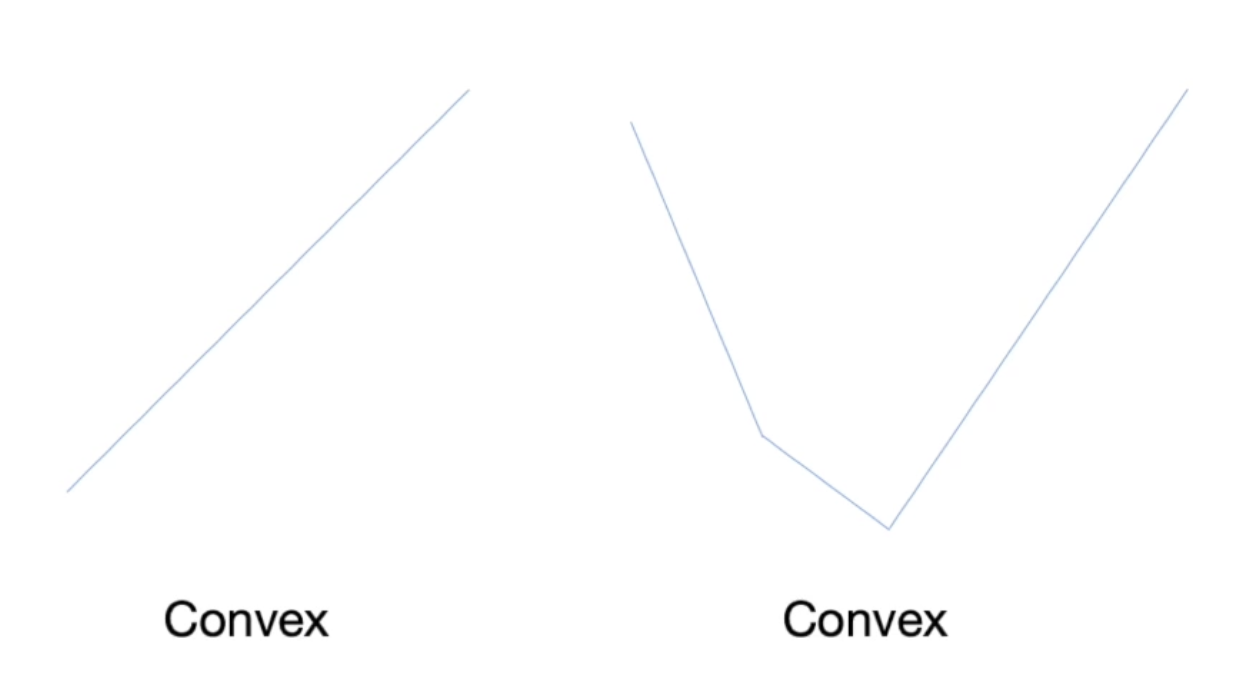

볼록성(Convexity)
두 점을 잡아 직선을 그었을 때 원래 있던 함수값보다 위에 있을 경우 Convex라고 이야기함
Loss Function을 Convex 형태로 만들 경우 최솟값을 찾기 쉬우므로 제일 좋음
Non-convex의 경우 시작 위치에 따라 global min으로 갈 수도 있고, local min으로 갈 수도 있기 때문에 최적화하는데 좋지 않음
Loss Function에서 max를 구하는 경우, Concave를 사용하면 좋음(-를 곱하면 min이 되므로 좋음)
두 점을 잡아 직선을 그었을 때 원래 있던 함수값보다 위에 있을 경우 Convex라고 이야기함
내용에 문제가 있으면 댓글로 알려주세요!
출처 : 인프런 - 실전 인공지능으로 이어지는 딥러닝 개념 잡기(딥러닝 호형)
'딥러닝 공부' 카테고리의 다른 글
| 장단기 메모리와 게이트 순환 유닛(LSTM and GRU) (0) | 2021.09.28 |
|---|---|
| 순환 신경망(Recurrent Neural Networks) (0) | 2021.09.23 |
| 인공 신경망의 최적화 - 확률적 경사 하강법과 최적화 기법 (0) | 2021.09.23 |
| 인공 신경망의 최적화 - 경사 하강법(Gradient Descent) (0) | 2021.09.23 |
| 인공 신경망의 최적화 - 하강법(Descent Method) (0) | 2021.09.23 |