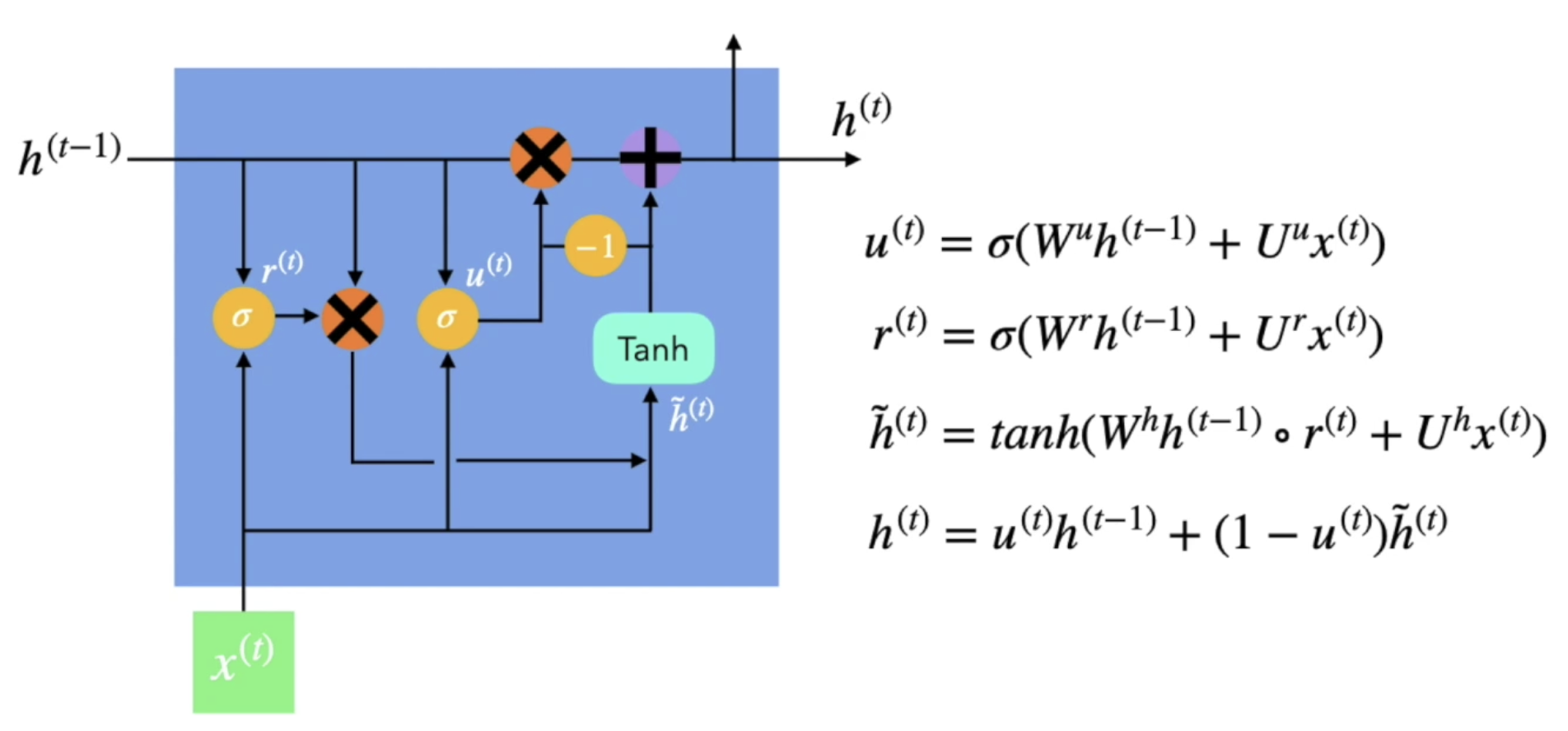
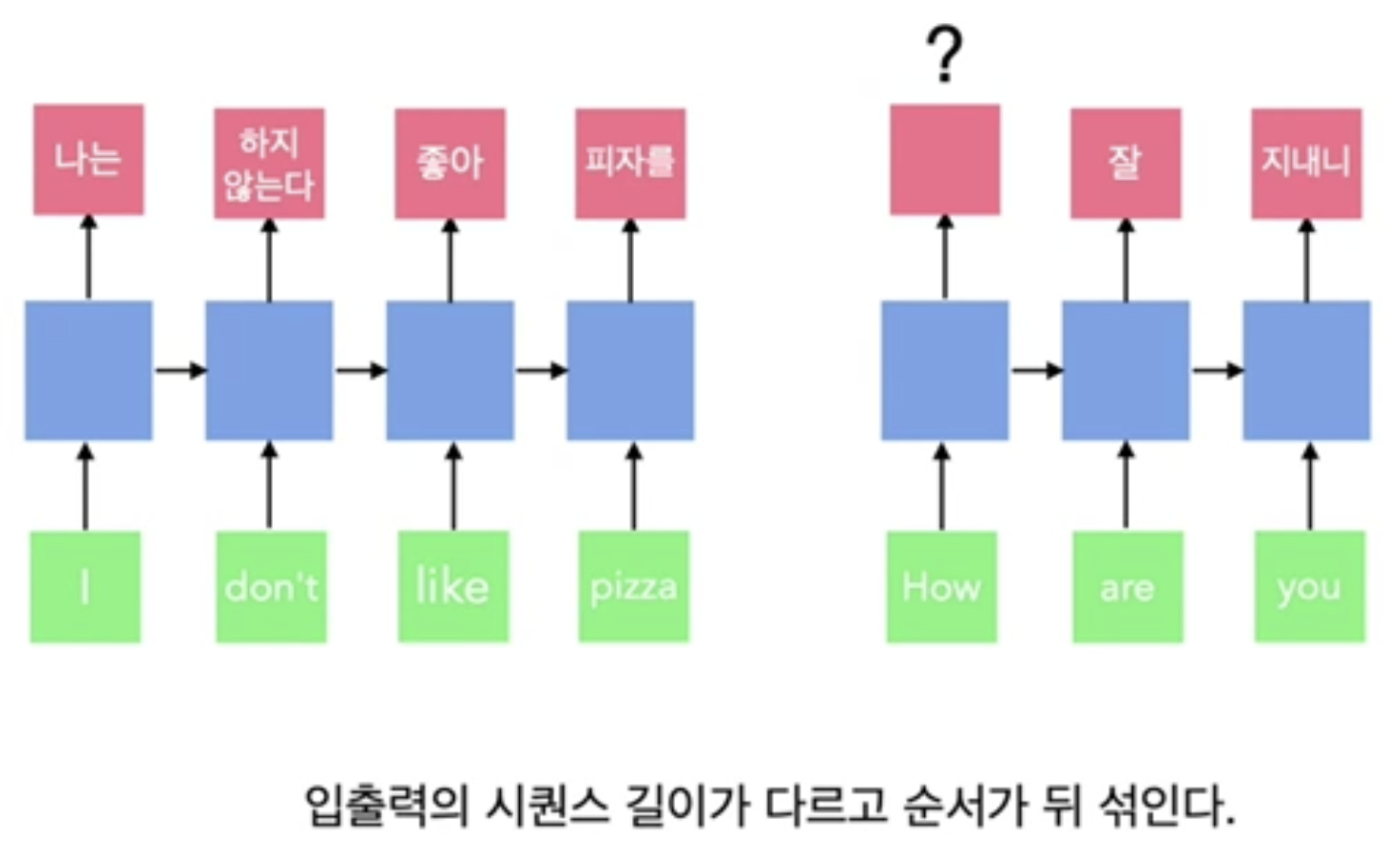
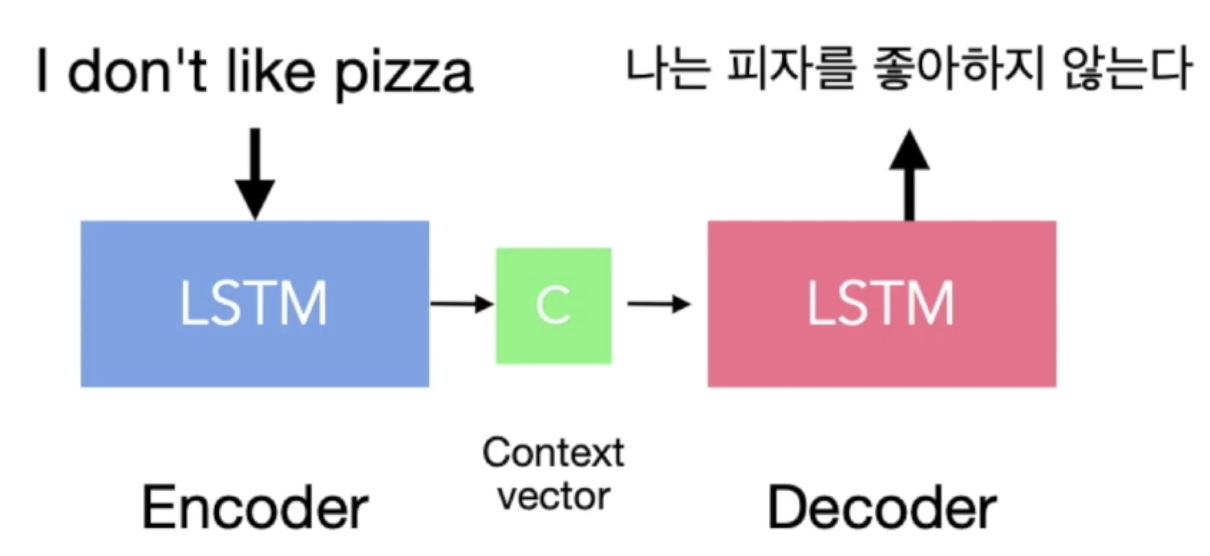
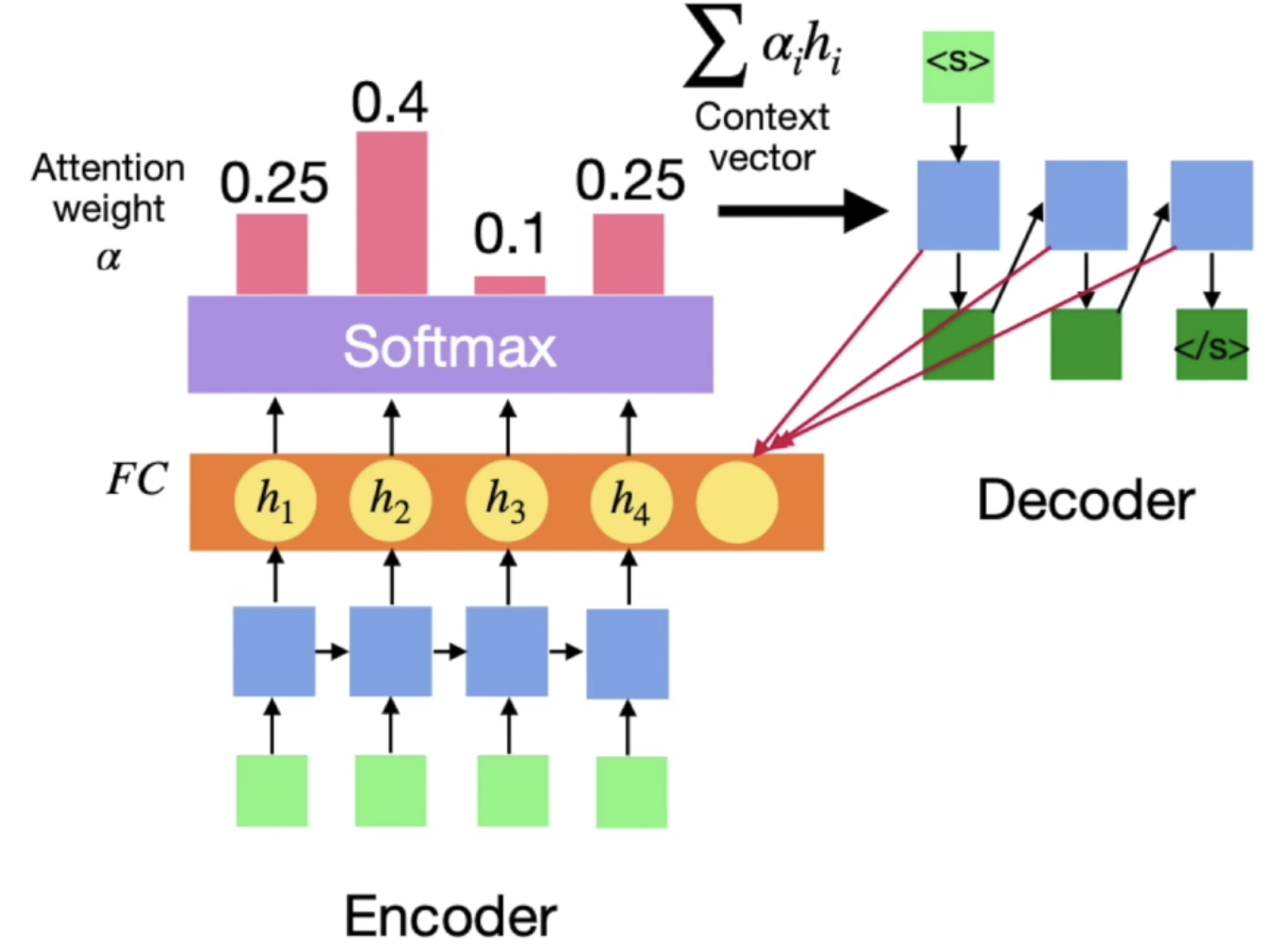
새로운 유형의 인공신경망인 오토 인코더란 무엇인지 알아보자!
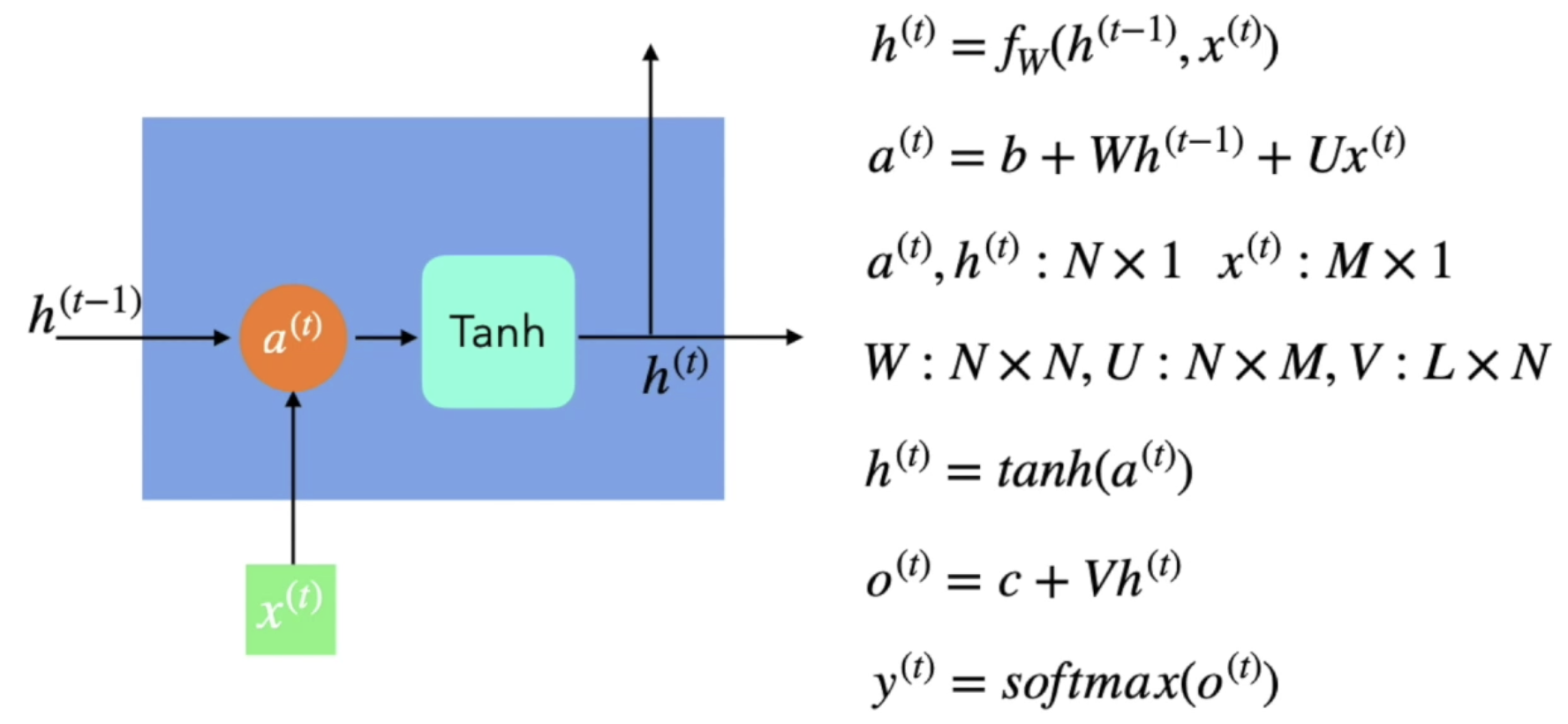
오토인코더(Autoencoder)

- 입력층과 출력층의 크기가 같은 형태(기본적인 형태)
- Encoder, Decoder로 나눠짐
- Latent Variables 기준으로 왼쪽을 보면 변수를 통해 특징이 추려지면서 중요한 값들로 압축이 됨 = Encoder
- 압축된 정보를 펼쳐서 원래 입력층과 유사한 값을 만들어냄 = Decoder
오토 인코더 특징
- 비지도 학습(unsupervised learning) : 실제 값이 없을 때 할 수 있는 학습 방법
- 지도 학습에서는 input값이 hidden state를 통해서 output이 나오는데, 이 output값을 실제 y값과 비교하여 Loss 값을 추출함
- 지도학습에서는 y값이 반드시 필요함
- 차원 축소 가능
- Encoder 부분을 보면 차원 축소를 할 수 있음
- PCA, clustering, Autoencoder를 통해서 차원 축소 가능
- 추가적인 이미지 생성 가능
- 이미지 뿐만 아니라 추가적인 변수 생성 가능
- 데이터가 모자를 경우에 오토인코더를 사용해서 데이터를 늘릴 수 있음
- 일반적으로 대칭 구조를 지님
- Encoder 부분과 Decoder 부분
학습 방법

- MSE를 사용해서 X값과 X' 값의 차이를 Loss function으로 정의해 줌
- y 값이 없기 때문에 y에 대한 지도학습 방법은 아님
- X와 X'의 차이가 작은 파라미터 값들을 업데이트 시켜줌
- 가중치 매트릭스 A, B, C, D
- A = 5 * 7
- B = 3 * 5
- C = 5 * 3
- D = 7 * 5
- 업데이트해야 할 변수의 개수 = 35 + 15 + 15 + 35 = 100
- 변수를 줄여주기 위해 C = B𝑇 , D = A𝑇 로 사용하는 경우도 있음 -> 이럴 경우 A와 B만 업데이트해도 C와 D도 업데이트됨
- 그래서 업데이트할 변수가 100개에서 50개로 줄어듦
오토 인코더의 종류
- Stacked Autoencoder(기본구조 - 여러 개의 은닉층 존재)
- 단점 : X와 X'로 Loss function을 정의해서 Loss를 작게 하는 가중치를 업데이트해줘야 하는데 Loss를 작게 해 주도록 업데이트하다 보면 X와 X'가 같은 값이 나올 수 있음 -> 그럼 Autoencoder를 사용하는 의미가 없음, 입력층의 값을 사용하지 왜 출력층의 값을 사용하니?
- Loss가 작아진다는 의미는? X와 X'가 같아야 한다는 소리
- 우리는 X라는 속성을 가진 X'를 얻고 싶은 것임
- 가깝지만 똑같지는 않고, 매우 유사한 X'를 얻고 싶음
- Denoising Autoencoder

- X라는 속성을 가진 X'를 얻고 싶어서 나온 것
- Autoencoder를 할 때 입력층 바로 다음에 노이즈를 주입함
- X에 대한 계산이 아닌 X + ε를 계산함
- 또는 입력층 바로 다음에 드랍아웃이라는 것을 사용해서 랜덤 한 일부 노드를 없애고 진행함
- Sparse Autoencoder

- X와 X'가 같게 나오면 모델이 의미가 없기 때문에 나옴
- X와 X'를 유사하게 만들기 위해 Loss function에 제약조건을 줘서 한없이 작아지지는 않게 함
- h = f(x), X' = g(h) => X' = g(f(x))
- Convolutional Autoencoder

- 말 그대로 CNN이 적용된 것
- Encoder와 Decoder는 모두 Convolutional Layer 형태로 채널들이 여러 개 있음
- h는 Convolutional 형태나 Linear 형태로 할 수 있음
- 1열 형태의 Layer를 사용하는 것이 아닌 Convolutional Layer를 사용하는 것
내용에 문제가 있으면 댓글로 알려주세요!
출처 : 인프런 - 실전 인공지능으로 이어지는 딥러닝 개념 잡기(딥러닝 호형)
'딥러닝 공부' 카테고리의 다른 글
| 인공 신경망의 성능 개선 - 데이터 불균형(Data Imbalance) (0) | 2021.09.28 |
|---|---|
| 인공 신경망의 성능 개선 - 과적합(Overfitting) (0) | 2021.09.28 |
| 장단기 메모리와 게이트 순환 유닛(LSTM and GRU) (0) | 2021.09.28 |
| 순환 신경망(Recurrent Neural Networks) (0) | 2021.09.23 |
| 인공 신경망의 최적화 - 기울기 사라짐, 손실함수와 최적화 (0) | 2021.09.23 |