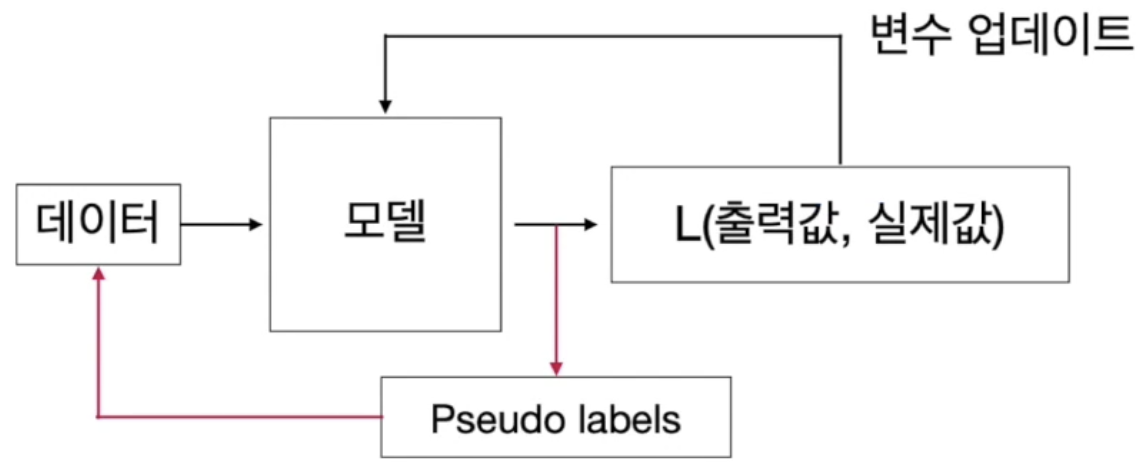
설명 가능한 AI는 무엇인지 알아보자!
딥러닝 모델은 내부적으로 어떻게 계산이 되는지 알아보기 쉽지 않고, 어떤 근거에 의해서 결과를 산출했는지 알기 어렵다.
XAI 중요성
- 결과 분석 용이
- 시각적 이해도 향상
- 모델 내부에 대한 이해도 향상
이미지 분야의 XAI
- Class Activation Map(CAM)
- 모델이 이미지를 분류하는데 이미지에서 어떤 부분을 가장 많이 받는지 시각화해줌
- Attention
- 이미지 안에서 어느 부분이 제일 두드러지는 가중치를 가지고 있는지 시각화해줌
- 이미지뿐만 아니라 시계열, 언어 분석에서도 사용 가능
- Activation Maxmization
- 특정 피쳐맵이 발현되려면 어떤 이미지가 들어왔을 때 가장 크게 발현되는지 시각화해줌
이번 강의에서는 이미지에서 처리 가능한 기술을 주로 설명해줘서 일단 패스!!
내용에 문제가 있으면 댓글로 알려주세요!
출처 : 인프런 - 실전 인공지능으로 이어지는 딥러닝 개념 잡기(딥러닝 호형)
'딥러닝 공부' 카테고리의 다른 글
| 향후 딥러닝 공부법 (0) | 2021.09.29 |
|---|---|
| 준지도 학습과 비지도 학습 (0) | 2021.09.29 |
| 인공 신경망의 성능 개선 - 전이 학습(Transfer Learning) (0) | 2021.09.28 |
| 인공 신경망의 성능 개선 - 모델 튜닝(Model Tuning) (0) | 2021.09.28 |
| 인공 신경망의 성능 개선 - 데이터 불균형(Data Imbalance) (0) | 2021.09.28 |