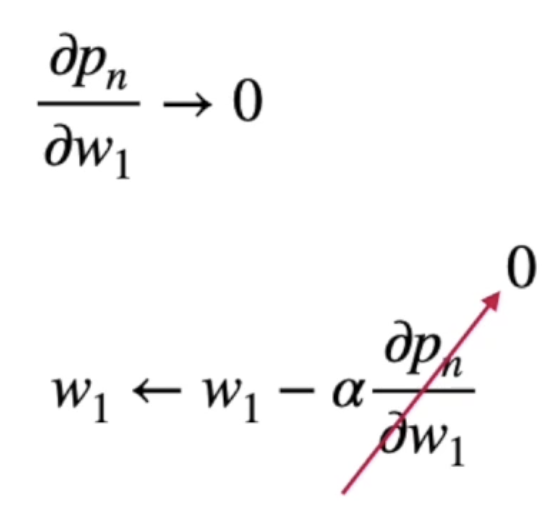순환 신경망의 다양한 형태들을 알아보쟈
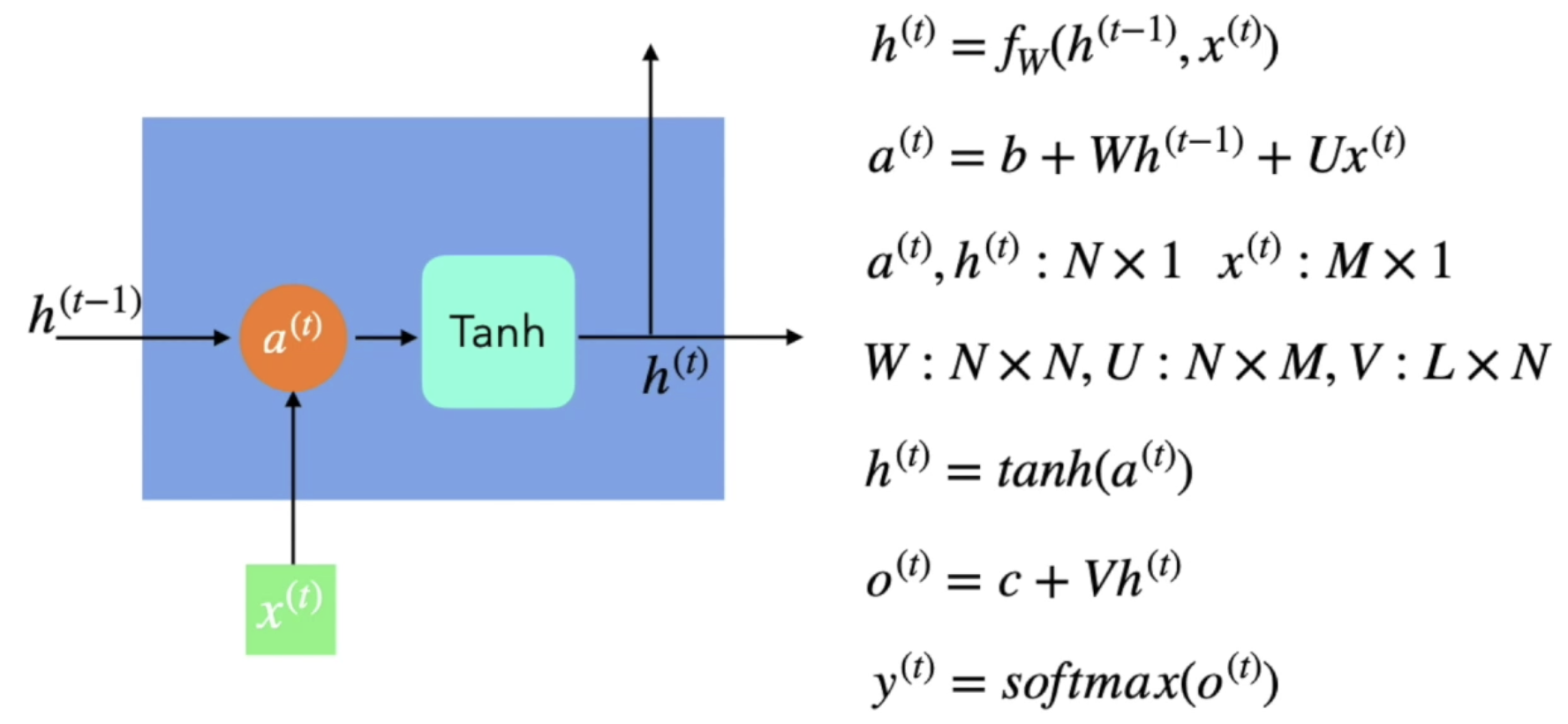
Vanilla RNN

- 이전 hidden state 정보를 받아서 현재 input 값과 계산을 한 뒤에, Tanh라는 activation function을 거쳐서 현재의 hidden statef를 만들어냄
- 이와 같은 방식을 사용하다 보면 '기울기 사라짐' 문제가 발생함
Vanilla RNN의 문제점


- '기울기 사라짐' 문제는 값이 조금만 커지거나 조금만 작아져도 미분 값이 0이 돼버리는 것
- '장기 의존성' 문제는 앞쪽의 hidden state 정보들이 뒷 쪽에 있는 hidden state까지 얼마나 전달이 될까? 라는 의문에서 생겨난 문제
LSTM(Long Short-Term Memory models)

- RNN의 '기울기 사라짐' 문제와 '장기 의존성' 문제를 보완하기 위해 나온 모델
- h값 만 받는 것이 아닌 s라는 gate를 만들어서 문제를 해결함
- 이전 정보를 얼마나 기억할지, 현재 정보를 얼마나 기억할지 구조를 만든 것
- 이전 정보가 덜 중요하다 싶으면 조금만 기억하고, 이전 정보가 중요한 것이면 많이 기억하는 식으로 동작함
- f : forget gate, i : input gate, o : output gate
- sell state, hidden state를 가지고 다음 계산에 반영시킴
- 장점 : 기존 RNN보다 좋은 성능을 가짐
- 단점 : 오래 걸림
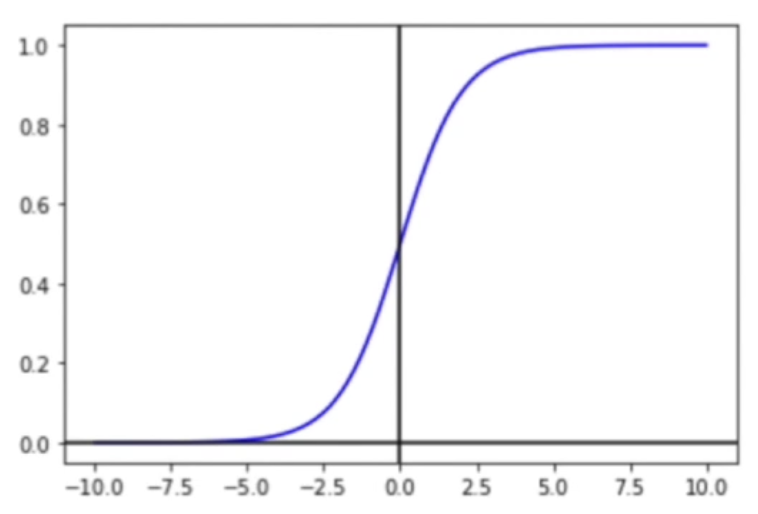
- sigmoid : 항상 0과 1 사이의 값을 가져옴
GRU(Gated Recurrent Unit)
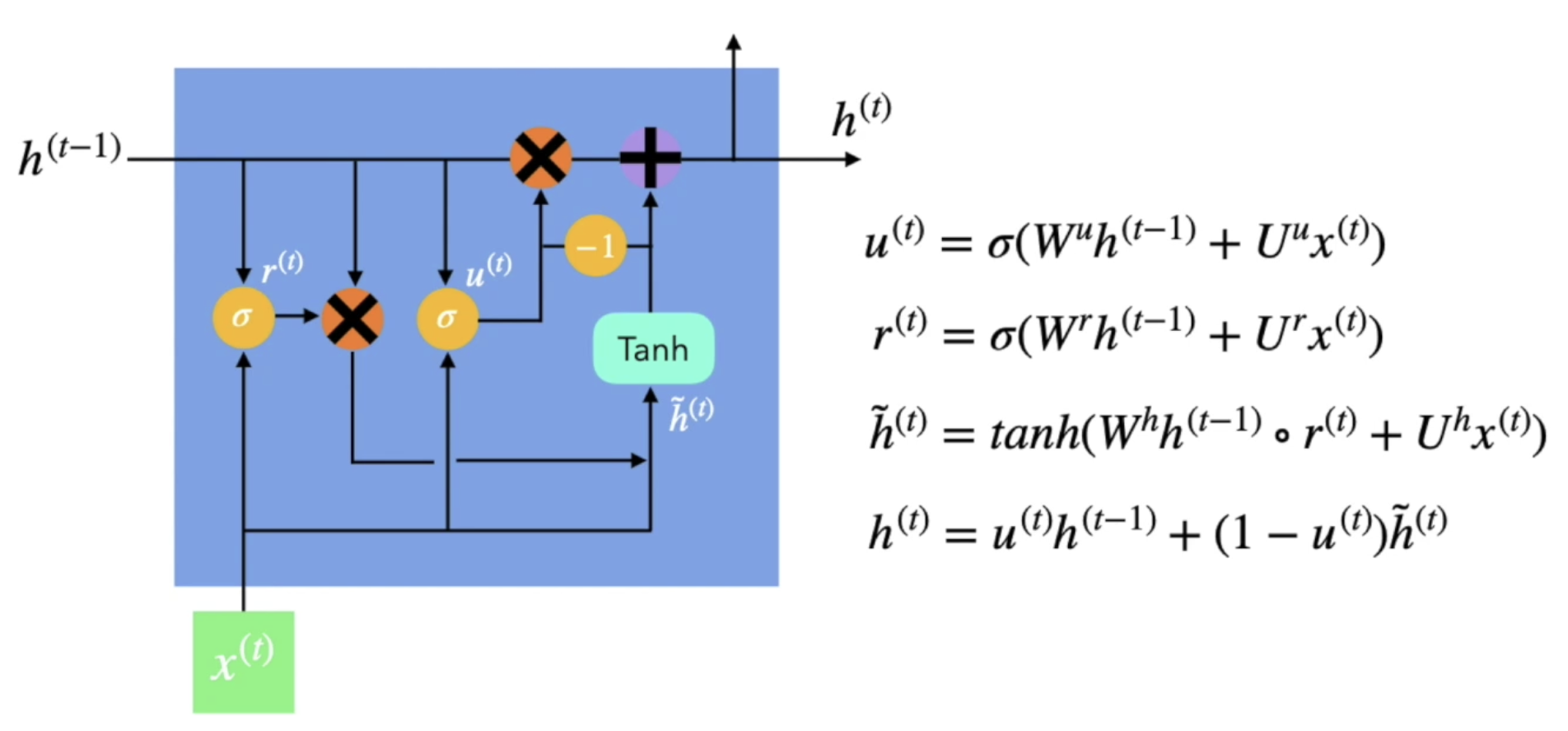
- LSTM 계산이 너무 복잡하니까, 계산을 줄여보자 해서 나온 모델
- r(t)가 0에 가까우면 이전 내용을 거의 반영하지 않겠다는 의미
- r(t)가 1에 가까우면 이전 내용을 많이 반영하겠다는 의미
- 다음으로 넘겨줄 h(t)를 만들 때는, 이전 정보를 살려서 더해주는 형태
- u(t)가 0에 가까우면 이전 정보는 조금, 현재 정보는 많이 반영하겠다는 의미
- u(t)가 1에 가까우면 이전 정보를 많이, 현재 정보를 조금 반영하겠다는 의미
RNN, LSTM, GRU의 근본적인 단점
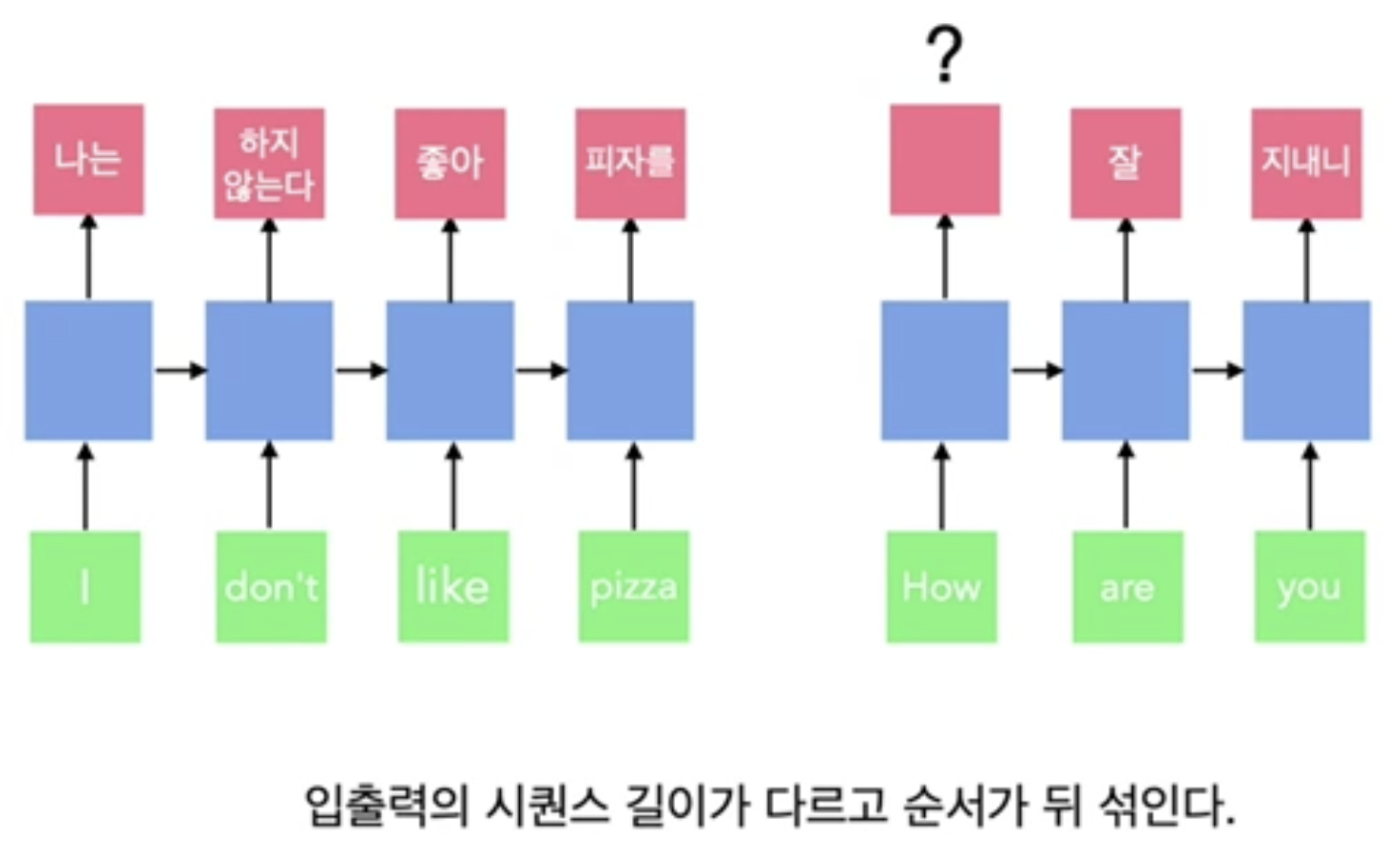
- many to many 번역 문제에서
- 기본적인 RNN 형태에서는 출력 길이를 조절할 수는 있지만 들어오는 문장마다 가변적일 수는 없음
- 순서를 고려하기 쉽지 않음
- 이런 문제를 해결하기 위해 seq2seq(sequence-to-sequence)가 나옴
seq2seq(sequence-to-sequence)
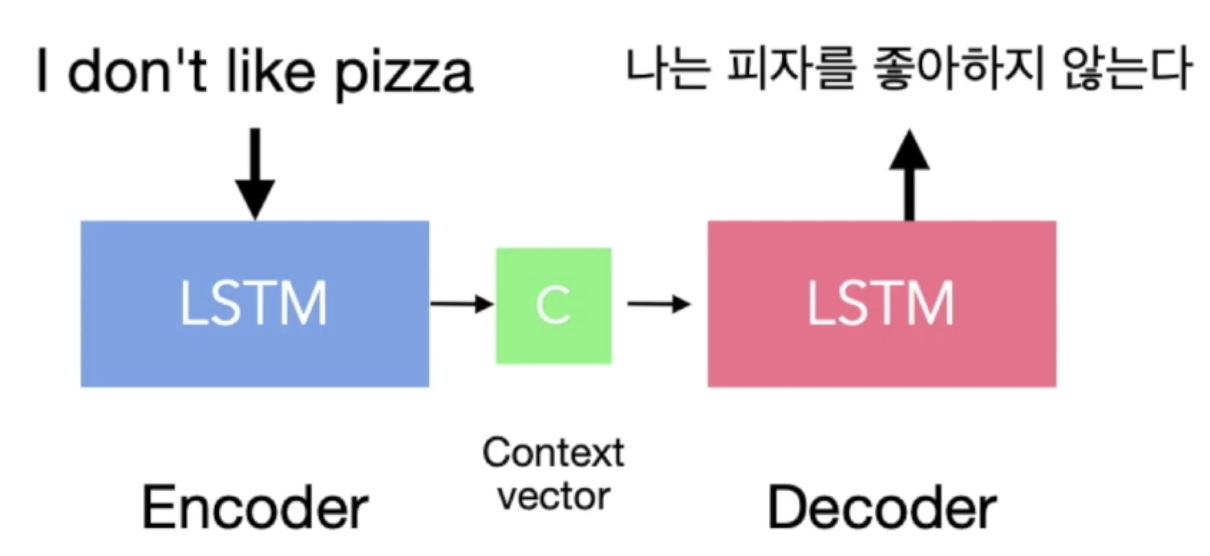
- LSTM 모델 두 개를 붙임
- 앞에 붙은 LSTM 모델을 Encoder라고 하고, 뒤에 붙은 LSTM 모델을 Decoder라고 함
- 입력 값에 대해 LSTM 모델을 통해서 분석을 한 뒤 거기에 대표되는 Context vector를 하나 만듦
- Context vector 정보를 뒤에 붙은 LSTM 모델로 보내서 처리함
- 이렇게 처리하기 때문에 input sequence의 개수와 output sequence의 개수가 달라도 상관없어짐(출력 길이에 구애받지 않음)
- context vector를 받아서 처리하기 때문에 input vector의 순서가 중요하지 않음
- 단점 : 어순을 판단하기 어려움
Attention Mechanism
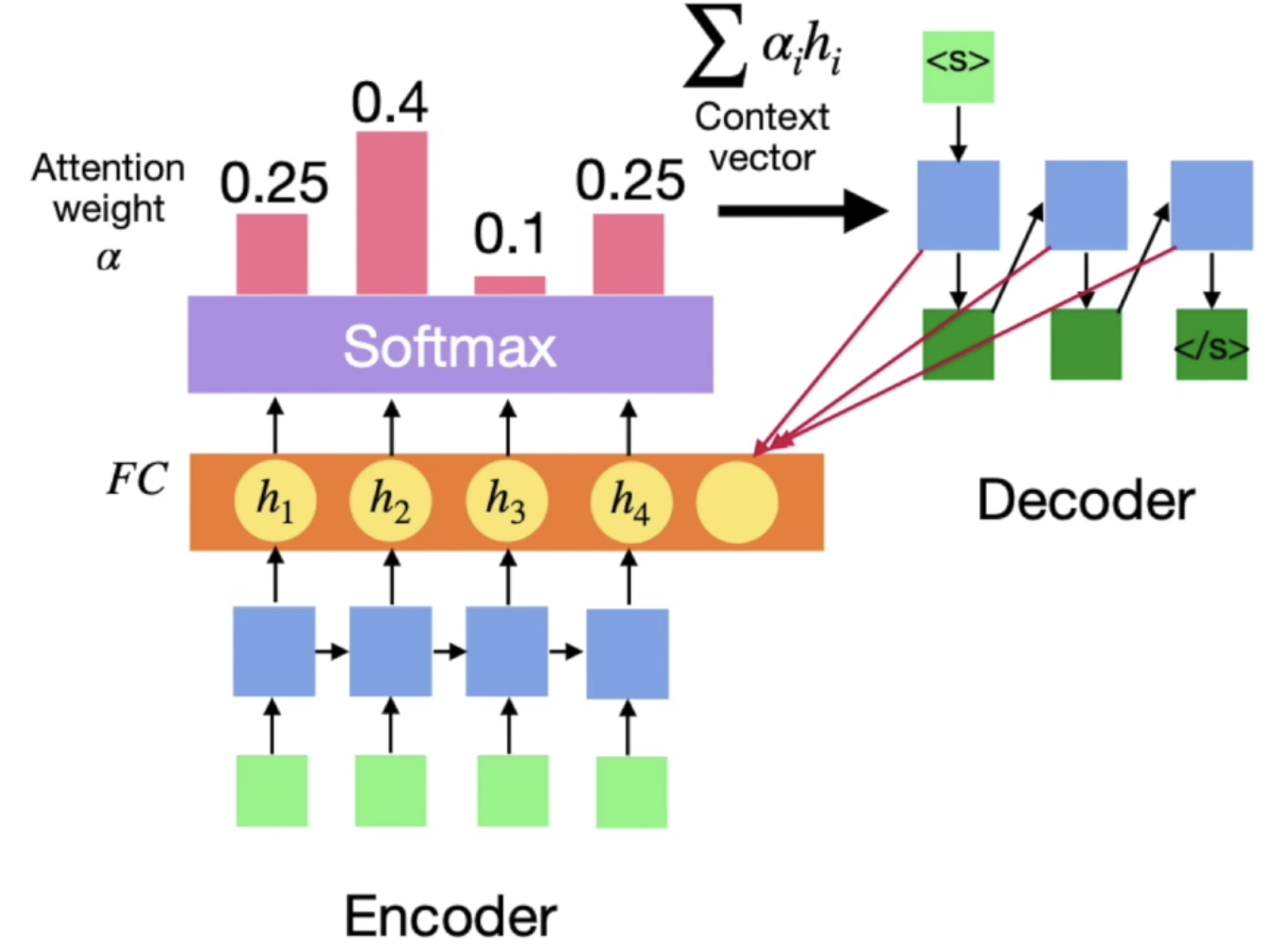
- seq2seq의 어순을 판단하기 어려운 문제점을 해결하기 위해 나옴
- 어순 차이를 극복함
- RNN 연산을 할 때 연산된 각각의 hidden state를 가지고 각각에 가중치를 구해서 hidden state각각에 가중치를 곱해서 더한 값을 context vector로 넘겨줌
- RNN의 고질적인 문제는 현재 정보가 과거의 정보에 영향을 미치지 않는다는 것
- 한 단어 한단어가 번역될 때마다 전체적인 문장에서 가중치를 구함으로서 어순과 상관없이 전체적인 문장을 고려할 수 있음
내용에 문제가 있으면 댓글로 알려주세요!
출처 : 인프런 - 실전 인공지능으로 이어지는 딥러닝 개념 잡기(딥러닝 호형)
'딥러닝 공부' 카테고리의 다른 글
| 인공 신경망의 성능 개선 - 과적합(Overfitting) (0) | 2021.09.28 |
|---|---|
| 오토인코더(Autoencoder) (1) | 2021.09.28 |
| 순환 신경망(Recurrent Neural Networks) (0) | 2021.09.23 |
| 인공 신경망의 최적화 - 기울기 사라짐, 손실함수와 최적화 (0) | 2021.09.23 |
| 인공 신경망의 최적화 - 확률적 경사 하강법과 최적화 기법 (0) | 2021.09.23 |