2. Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova, "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding"(https://arxiv.org/pdf/1810.04805.pdf)
- Siamese과 triplet network 구조를 적용함으로써 기존에 BERT가 하지 못했던 "large-scale semantic similarity comparison, clustering, and information retrieval via semantic search" 태스크에 사용할 수 있었다.
- BERT에 두 개의 문장이 transformer network에 전달되고 target value가 예측된다.
- clustering 및 semantic search 처리하는 일반적인 방법은 의미가 유사한 각 문장을 벡터 공간상에 가깝도록 맵핑하는 것이다.
- BERT에 개별 문장을 입력하고 고정된 크기의 문장 임베딩을 도축하기 시작했는데, 가장 일반적인 방법은 output layer을 평균을 내거나 첫 번째 토큰([CLS] 토큰)의 출력을 사용하는 것이다. 이 방법은 GloVe 임베딩에 평균을 내는 것보다 안좋다.
- 그래서 나온 것이 SBERT(Sentence-BERT)이다.
- siamese network architecture를 사용하면 입력 문장에 대해 고정 된 크기의 벡터를 유도할 수 있다.
- cosine similarity, Manhatten / Euclidean distance와 같은 유사도 측정 방법을 사용하면 의미적으로 유사한 문장을 찾을 수 있다.
- NLI 데이터로 SBERT를 fine tuning 하여 InferSent 및 Universal Sentence Encoder와 같은 SOTA sentence embedding methods보다 성능을 높였다.
- config 함수 생성 후에 answer 구절에 해당하는 ID와 텍스트를 포함하도록 Document 정의한다.
from jina import Document
def index_generator():
import csv
data_path = os.path.join(os.path.dirname(__file__), os.environ['JINA_DATA_PATH'])
# Get Document and ID
with open(data_path) as f:
reader = csv.reader(f, delimiter='\t')
for data in enumerate(reader):
d = Document()
d.tags['id'] = int(data[0])
d.text = data[1]
yield d
1-2. Endocing our data to embeddings
- Answer Passage를 인코딩한다.
- Jina는 Drivers를 사용하여 Executor용 데이터를 translate 하므로, 익숙한 데이터 유형(예: 텍스트, 이미지, np, 배열 등)만 사용하면 된다.
- 인코딩 단계에서 Driver는 Document를 Byte 단위로 수신하여 Document를 해석하고, Document의 텍스트를 인코더에 전달한다.
- 인코더가 해당 텍스트에 대한 Embedding을 출력한 후, 동일한 Driver가 Embedding을 다시 해석하여 Document에 추가한다.
- Pea : Executor는 데이터를 처리할 수 있는 Driver가 필요하기 때문에 둘 다 Flow에서 마이크로 서비스의 필수 구성 요소이다. 따라서 우리는 Encoder Microservice를 얻기 위해 Pea를 사용하여 Executor와 Driver를 함께 wrapping 한다. Pea는 게이트웨이 또는 Flow의 다른 Peas에서 들어오는 메시지를 지속적으로 수신 대기하고 메시지를 수신할 때 Driver를 호출하는 마이크로 서비스이다.
- Pod : 신경 검색 애플리케이션을 최적화하기 위해 Jina는 기본적으로 병렬화를 제공한다. 단일 인코더를 사용하는 대신 여러 프로세스로 분할할 수 있다. multiple Encoder microservice가 하나의 Encoder처럼 기능적으로 작동하도록 하기 위해 Peas 그룹을 Pod에 wrapping 한다. Pod는 load balancing, further control, context management를 담당하는 microservice 그룹이다.
- 이 디자인의 장점은 Pod가 로컬 호스트 또는 네트워크를 통해 서로 다른 컴퓨터에서 실행될 때, 애플리케이션을 분산시키고, 효율적이며 확장 가능하다는 것이다.
- Jina가 제공하는 building block을 사용하여 아래 2가지를 할 수 있다.
1) design an Index Flow
2) create an Encoder Pod with two simple YAML files
1. Create a Pod for the Encoder
- 먼저 pods 폴더 안에 encode.yml 파일을 생성한 후, Jina Hub에서 사용할 Encoder이름을 지정한다.
!사용할 인코더 이름
with:
pool_strategy: auto
pretrained_model_name_or_path: model/모델이름
max_length: 512
2. Add the Encoder to the Index Flow
- 위에서 Encoder가 준비되었으므로, Index Flow를 만들어 본다.
- flows 폴더 안에 index.yml 파일을 생성한 후, Index Flow에서 첫 번째 Pod를 지정한다.
- answer에 대한 Embedding을 얻은 후 Query time에 검색할 수 있도록 데이터를 저장하기 위해 Indexer라는 또 다른 Executor를 만든다.
- 이전 단계와 유사하게 Driver는 Document를 수신하고 docid, doc 및 Embedding을 Indexer한테 전달한다.
- Jina Hub의 (1)Vector 와 (2)Key-Value Indexer를 모두 사용하여 단일 Indexer 역할을 하는 복합 Indexer을 사용한다.
(1)Vector Indexer : k-nearest neighbors algorithm을 사용하여 가장 가까운 answer Embedding을 검색하기 위해 answer Embedding을 저장하고 question Embedding으로 query된다.(뭐라고 해석해야 할 지 모르겠다ㅠㅠ..)
(2)Key-Value(KV) Indexer : Document Data(텍스트, blob, 메타데이터)를 저장하고, docid(일반적으로 벡터 인덱서에서 추출)로 쿼리하여 answer id 및 텍스트와 같은 데이터 정보를 검색한다.
- 검색 애플리케이션에서 인덱스 흐름을 사용하는 방법을 살펴보자. app.py에서 config 함수에서 parallel을 변경하여 각 Pod에 대해 각 마이크로 서비스를 분할하려는 Peas(프로세스) 수를 나타낼 수 있다. 인덱싱 단계에서 parallelization를 나타내기 위해 shard를 변경할 수도 있다. 아래 코드에서는 둘 다 변경되지 않은 상태로 둔다. 이것은 각 Pod에 하나의 Pea만 가질 것임을 의미한다.
- Step1. Define our data에서 추가한 index_generator 함수 이후에, 먼저 Flows/index.yml 에서 생성한 Index Flow를 로드하고 index_generator의 입력 Document를 플로우로 전달하는 index 함수를 추가한다. answer 구절을 임베딩으로 인코딩하기 위해 batch_size=16을 설정한다.
from jina.flow import Flow
def index():
f = Flow.load_config('flows/index.yml')
with f:
f.index(input_fn=index_generator, batch_size=16)
- Data를 Index할 준비가 되었으니 실행을 시켜보자.
python app.py index
Driver와 Indexer를 Pea 안에서 wrapping하고, Peas를 Pod로 그룹화하고, YAML 파일을 사용하여 정의한다.
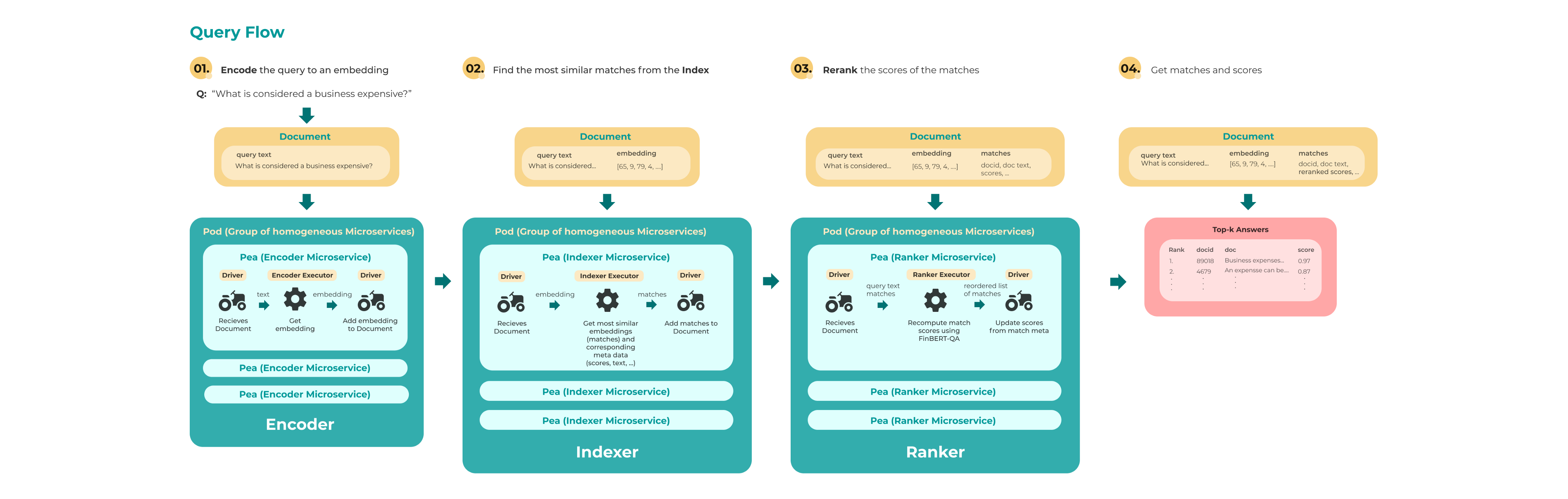
- 데이터를 인덱싱한 후 Query Flow를 만들어야 한다. Query Flow의 기본 아이디어는 동일한 BERT 기반 모델을 사용하여 주어진 질문을 임베딩으로 인코딩하고 인덱서를 사용하여 가장 유사한 답변 임베딩을 검색하는 것이다. 검색 결과를 더욱 향상시키기 위해 저자의 순위 재지정 기술을 사용한다. 따라서 FinBERT-QA를 사용하여 Jina가 반환한 답변 일치의 점수를 다시 계산하는 또 다른 순위 변경 단계를 추가해야 한다.
2-1. Encode the query to an embedding
- 사용자가 입력한 질문(Question) 텍스트를 Jina의 Document 타입으로 정의한다.
- Query Flow에 Encoder 추가한다. Index Flow와 마찬가지로 동일한 Encoder를 사용하여 질문을 Encoding한다.
- Query Flow에서 pods/encode.yml의 동일한 Encoder를 사용할 수 있다. flows 폴더에 query.yml 파일을 만들고 여기에 Encoder Pod를 추가한다.
- Indexer가 이 시점에서 Top-k개 answer 일치 항목을 반환하고 더 나은 결과를 얻기 위해 match score를 다시 계산한다고 가정해보자. Jina에는 Rankers라는 Executors class가 있는데, 특히 Match2DocRankers는 new score를 계산하여 쿼리의 match score를 다시 매긴다. Jina Hub의 Rankers를 보면, Levenshtein Ranker는 Levenshtein distance를 사용하여 match score를 다시 계산한다.
- 그러나 disteance matric을 사용하여 점수를 다시 계산하는 대신, Ranker에 fine-tuned(미세 조정된) BERT 모델인 FinBERT-QA를 로드하고 binary classification task에 대한 입력으로 질문과 현재 일치 답변의 연결을 사용하여 점수를 다시 계산한다.
- 여기서 주요 아이디어는 FinBERT-QA에서 계산한 relevancy score를 기준으로 재정렬된 일치 목록을 반환하기 위해 query text와 일치 항목(answer text 및 match score 포함)을 랭커에 전달하는 것이다. Driver는 다시 정렬된 목록을 기반으로 Document의 일치 항목을 업데이트한다.
from jina.executors.rankers import BaseRanker
class FinBertQARanker(BaseRanker):
"""
:class:`FinBertQARanker` recomputes match scores using FinBERT-QA.
"""
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
# your customized __init__ below
raise NotImplementedError
def score(self, *args, **kwargs):
raise NotImplementedError
- Jina는 다양한 Executor 클래스를 포함하고 있으며, 여기서 사용할 기본 Ranker 클래스는 Match2DocRankers라고 하며, 일치 점수를 다시 계산하는 기능이 있다.
- 먼저 BaseRanker의 기본 클래스를 Match2DocRanker로 변경한다. 또한 Jina와 현재 디렉토리를 정의할 뿐만 아니라 필요한 다른 모듈을 사용하여 PyTorch를 가져온다.
import os
from typing import Dict
import numpy as np
from jina.executors.devices import TorchDevice
from jina.executors.rankers import Match2DocRanker
cur_dir = os.path.dirname(os.path.abspath(__file__))
- 로직은 Jina의 TorchDevice 및 Match2DocRanker를 사용하는 FinBertQARanker 클래스에서 구현된다. 나중에 Dockerfile에 필요한 모델을 다운로드한다.
- models 폴더에 (1) bert-qa 및 (2) 2_finbert-qa-50_512_16_3e6.pt 라는 두 가지 모델이 있다고 가정해보자.
(1) bert-qa : BERT를 사용한 Passage Re-ranking의 MS 매크로 데이터 세트에서 미세 조정된 bert-base-uncased
(2) 2_finbert-qa-50_512_16_3e6.pt: FinBERT-QA 모델 - FiQA 데이터 세트에서 미세 조정된 bert-qa
- 먼저 초기화에 사용할 사전 훈련된 모델로 bert-qa/를 지정하고
- QA relevancy score를 계산하는 데 사용할 모델로 2_finbert-qa-50_512_16_3e6.pt를 지정하고
- QA의 최대 시퀀스 길이를 지정한다.
class FinBertQARanker(TorchDevice, Match2DocRanker):
"""
:class:`FinBertQARanker` Compute QA relevancy scores using a fine-tuned BERT model.
"""
required_keys = {"text"}
def __init__(
self,
pretrained_model_name_or_path: str = os.path.join(cur_dir, "models/bert-qa"),
model_path: str = os.path.join(cur_dir, "models/2_finbert-qa-50_512_16_3e6.pt"),
max_length: int = 512,
*args, **kwargs):
"""
:param pretrained_model_name_or_path: the name of the pre-trained model.
:param model_path: the path of the fine-tuned model.
:param max_length: the max length to truncate the tokenized sequences to.
"""
super().__init__(*args, **kwargs)
self.pretrained_model_name_or_path = pretrained_model_name_or_path
self.model_path = model_path
self.max_length = max_length
- 그런 다음 Hugging Face transformer을 사용하여 binary classification task에 대한 모델을 로드하기 위해 클래스에 post_init 함수를 추가한다. evaluation mode에서 모델을 설정해야 한다.
- _get_score 함수를 구현하여 질문의 relevancy score와 Top-k개 매칭된 답변을 각각 계산한다. 먼저 질문과 각 top-k 답변을 연결하고 변환하여 tokenizer를 사용하여 모델에 필요한 입력( input_ids, token_type_ids, att_mask)을 얻기 위해 인코딩한다.
- 그런 다음 input을 모델에 입력하고 QA 쌍이 관련이 있다는 prediction score를 얻는다(label = 1). prediction score를 0과 1 사이의 확률로 변환하기 위해 점수에 softmax 함수를 적용한다. output은 QA 쌍에 대한 확률 형태의 relevancy score가 된다.
def _get_score(self, query, answer):
import torch
from torch.nn.functional import softmax
# Create input embeddings for the model
encoded_seq = self.tokenizer.encode_plus(query, answer,
max_length=self.max_length,
pad_to_max_length=True,
return_token_type_ids=True,
return_attention_mask=True)
# Numericalized, padded, clipped seq with special tokens
input_ids = torch.tensor([encoded_seq['input_ids']]).to(self.device)
# Specify which position of the embedding is the question or answer
token_type_ids = torch.tensor([encoded_seq['token_type_ids']]).to(self.device)
# Specify which position of the embedding is padded
att_mask = torch.tensor([encoded_seq['attention_mask']]).to(self.device)
# Don't calculate gradients
with torch.no_grad():
# Forward pass, calculate logit predictions for each QA pair
outputs = self.model(input_ids, token_type_ids=token_type_ids, attention_mask=att_mask)
# Get the predictions
logits = outputs[0]
# Apply activation function to get the relevancy score
rel_score = softmax(logits, dim=1)
rel_score = rel_score.numpy()
# Probability that the QA pair is relevant
rel_score = rel_score[:, 1][0]
return rel_score
- 마지막으로,사용자와 Jina의 match score를 입력으로 가져와서 _get_scores를 사용하여 new score를 다시 계산하는 scoring function 를 만든다.
- 새로운 Executor를 생성하고 Jina Hub API를 사용하여 Docker 이미지를 빌드하려면 단위 테스트를 작성해야 한다. tests/test_finbertqaranker.py에서 이에 대한 템플릿을 찾을 수 있다. 쿼리가 주어진 두 개의 답변 일치에 대한 관련성 확률을 계산하고 FinBertQARanker가 우리의 예상과 동일한 점수를 계산하는지 확인하기 위해 간단한 검사를 작성한다.
import copy
import json
import numpy as np
import torch
from torch.nn.functional import softmax
from transformers import BertTokenizer, BertForSequenceClassification
from jina.executors.rankers import Match2DocRanker
from .. import FinBertQARanker
def test_finbertqaranker():
"""here is my test code
https://docs.pytest.org/en/stable/getting-started.html#create-your-first-test
"""
query_meta = {"text": "Why are big companies like Apple or Google not included in the Dow Jones Industrial "
"Average (DJIA) index?"}
query_meta_json = json.dumps(query_meta, sort_keys=True)
old_match_scores = {1: 5, 2: 7}
old_match_scores_json = json.dumps(old_match_scores, sort_keys=True)
match_meta = {1: {"text": "That is a pretty exclusive club and for the most part they are not interested in "
"highly volatile companies like Apple and Google. Sure, IBM is part of the DJIA, "
"but that is about as stalwart as you can get these days. The typical profile for a "
"DJIA stock would be one that pays fairly predictable dividends, has been around since "
"money was invented, and are not going anywhere unless the apocalypse really happens "
"this year. In summary, DJIA is the boring reliable company index."},
2: {"text": "In most cases you cannot do reverse lookup on tax id in the US. You can "
" verify , but for that you need to have more than just the FEIN/SSN. You "
"should also have a name , and some times address. Non-profits , specifically "
", have to publish their EIN to donors , so it may be easier than others "
"to identify those. Other businesses may not be as easy to find just by "
"EIN."}}
match_meta_json = json.dumps(match_meta, sort_keys=True)
pretrained_model = 'models/bert-qa'
model_path = "models/2_finbert-qa-50_512_16_3e6.pt"
ranker = FinBertQARanker(pretrained_model_name_or_path=pretrained_model, model_path=model_path)
new_scores = ranker.score(
copy.deepcopy(query_meta),
copy.deepcopy(old_match_scores),
copy.deepcopy(match_meta)
)
# new_scores = [(1, 0.7607551217079163), (2, 0.0001482228108216077)]
np.testing.assert_approx_equal(new_scores[0][1], 0.7607, significant=4)
np.testing.assert_approx_equal(round(new_scores[1][1], 4), 0.0001, significant=4)
# Guarantee no side-effects happen
assert query_meta_json == json.dumps(query_meta, sort_keys=True)
assert old_match_scores_json == json.dumps(old_match_scores, sort_keys=True)
assert match_meta_json == json.dumps(match_meta, sort_keys=True)
4) Add Requirements
- Jina 외에도 FinBertQARanker용 PyTorch 및 transformer를 사용하고 있으므로 FinBertQARanker/requirements.txt에 추가한다.
torch==1.7.1
transformers==4.0.1
** Dockerfile 관련해서는 아래 내용 참고!
5) Prepare Dockerfile
- Dockerfile을 아래 내용으로 변경하면 모델이 models/이라는 폴더에 다운로드된다.
6) Build Docker image with Jina Hub API
- FinBertQARanker를 Docker 이미지로 빌드할 준비가 완료된 후, 작업 디렉토리에 아래 내용을 입력한다.
--pull :로컬이 아닌 경우 Jina 기본 이미지를 다운로드한다.
--test-uses:빌드된 이미지가 Jina의 Flow API를 통해 성공적으로 테스트 실행될 수 있는지 확인하는 추가 테스트를 추가한다.
--timeout-ready:post_init 함수에 모델을 로드할 시간을 준다.
5) Prepare Dockerfile
- Dockerfile을 아래 내용으로 변경하면 모델이 models/이라는 폴더에 다운로드된다.
FROM jinaai/jina
RUN apt-get update && \
apt-get -y install wget && \
apt-get -y install unzip
COPY ./requirements.txt /
RUN pip install -r requirements.txt
RUN pip uninstall -y dataclasses
RUN pip install pytest
RUN wget https://www.dropbox.com/s/sh2h9o5yd7v4ku6/bert-qa.zip
RUN wget https://www.dropbox.com/s/12uiuumz4vbqvhk/2_finbert-qa-50_512_16_3e6.pt
# setup the workspace
COPY . /workspace
WORKDIR /workspace
RUN if [ ! -d models ]; then \
mkdir models/ && cd models/ && \
mv /bert-qa.zip . && \
mv /2_finbert-qa-50_512_16_3e6.pt . && \
mkdir bert-qa && \
unzip bert-qa.zip -d bert-qa/; \
fi
RUN pytest
ENTRYPOINT ["jina", "pod", "--uses", "config.yml"]
6) Build Docker image with Jina Hub API
- FinBertQARanker를 Docker 이미지로 빌드할 준비가 완료된 후, 작업 디렉토리에 아래 내용을 입력한다.
jina hub build FinBertQARanker/ --pull --test-uses --timeout-ready 60000
--pull :로컬이 아닌 경우 Jina 기본 이미지를 다운로드한다.
--test-uses:빌드된 이미지가 Jina의 Flow API를 통해 성공적으로 테스트 실행될 수 있는지 확인하는 추가 테스트를 추가한다.
--timeout-ready:post_init 함수에 모델을 로드할 시간을 준다.
1) Create a custom Ranker Pod
- 사용자 지정 Ranker인 FinBertQARanker를 사용하려면 먼저 Ranker에 대한 새 Pod를 만든다. pods 폴더에 rank.yml 파일을 생성한 후 FinBertQARanker/config.yml의 내용을 pods/rank.yml로 복사한다.
- Executor는 FinBertQARanker/__init__.py에서 구현한 로직을 사용하도록 Query Flow에 지시한다. 이 구현을 위한 코드는 Docker 이미지의 workspace 폴더 안에 로드되므로 __init__.py 앞에 workspace/를 추가한다.
- 지금까지 사용한 Encoder 및 Indexer Executor는 모두 Pod의 기본 Driver를 사용한다. Custom Executor를 생성했으므로 Ranker Pod에 사용할 Driver를 알려야 합니다. 이 경우 Match2DocRanker 기본 Ranker 클래스에 Matches2DocRankDriver를 사용한다.
!FinBertQARanker
with:
{}
metas:
py_modules:
- workspace/__init__.py
# - You can put more dependencies here
requests:
on:
[ SearchRequest ]:
- !Matches2DocRankDriver { }
2) Use Custom Ranker in the Query Flow
- 다른 Executor Pod와 마찬가지로 doc_indexer 뒤에 ranker를 추가하고 태그 이름 앞에 docker:// 접두사를 지정하여 방금 생성한 Docker 이미지와 Ranker Pod를 사용하도록 Query Flow에 지시한다.
- Docker 이미지의 태그 이름은 현재 Jina 릴리스에 따라 변경될 수 있기 때문에 그때마다 태그 이름을 변경해야 한다.
- Flow API를 사용하여 쿼리 흐름을 다시 시각화할 수 있다.
from jina.flow import Flow
f = Flow.load_config('flows/query.yml')
f.plot()
- 여기에서 Encoder인 encoder 및 Indexer인 doc_indexer 및 Ranker인 ranker를 포함하는 세 개의 Pod가 있는 Query Flow을 볼 수 있다.
- Query Flow이 끝나면 Ranker Pod의 Driver가 Custom Ranker인 FinBertQARanker가 계산한 확률을 기반으로 Document의 일치 항목을 재정렬된 일치 목록으로 변경한다.
2-4. Get matches and scores
* Build a Search Application
- 최종 일치 항목과 relevancy 확률이 Document에 저장되어 있기 때문에 app.py에서 사용자 입력의 질문에 대한 응답을 출력하는 함수를 작성한다.
- Document, d.matches에서 일치 항목을 반복하고 점수 값과 일치하는 답변 텍스트를 출력한다.
def print_resp(resp, question):
for d in resp.search.docs:
print(f"🔮 Ranked list of answers to the question: {question}: \n")
for idx, match in enumerate(d.matches):
score = match.score.value
answer = match.text.strip()
print(f'> {idx+1:>2d}. "{answer}"\n Score: ({score:.2f})')
- 그런 다음 flows/query.yml의 Query Flow을 사용하는 검색 방법을 작성하고 사용자 입력을 print_resp에 전달한다.
- f.search_lines()의 멋진 점은 사용자 쿼리에 대한 문서를 자동으로 생성한다는 것이다.
def search():
f = Flow.load_config('flows/query.yml')
with f:
while True:
text = input("Please type a question: ")
if not text:
break
def ppr(x):
print_resp(x, text)
f.search_lines(lines=[text, ], output_fn=ppr, top_k=50)